



Log-odds是自然对数odds的简写方式。当你采用某种东西的自然对数时,你基本上可以使它更正常分布。当我们制作更正常分布的东西时,我们基本上把它放在一个非常容易使用的尺度上。
当我们采用log-odds时,我们将odds的范围从0正无穷大转换为负无穷正无穷大。可以在上面的钟形曲线上看到这一点。
即使我们仍然需要输出在0-1之间,我们通过获取log-odds实现的对称性使我们比以前更接近我们想要的输出!
Logit函数
“logit函数”只是我们为了得到log-odds而做的数学运算!
恐怖的不可描述的数学。呃,我的意思是logit函数。
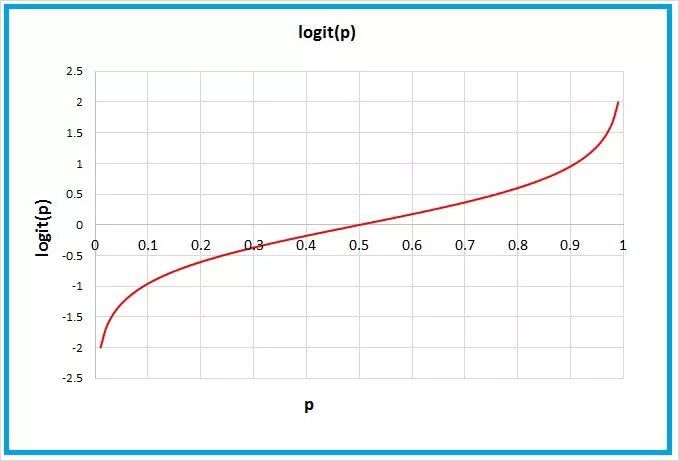
logit函数,用图表绘制
正如您在上面所看到的,logit函数通过取其自然对数将我们的odds设置为负无穷大到正无穷大。
Sigmoid函数
好的,但我们还没有达到模型给我们概率的程度。现在,我们所有的数字都是负无穷大到正无穷大的数字。名叫:sigmoid函数。
sigmoid函数,以其绘制时呈现的s形状命名,只是log-odds的倒数。通过得到log-odds的倒数,我们将我们的值从负无穷大正无穷大映射到0-1。反过来,让我们得到概率,这正是我们想要的!
与logit函数的图形相反,其中我们的y值范围从负无穷大到正无穷大,我们的sigmoid函数的图形具有0-1的y值。好极了!
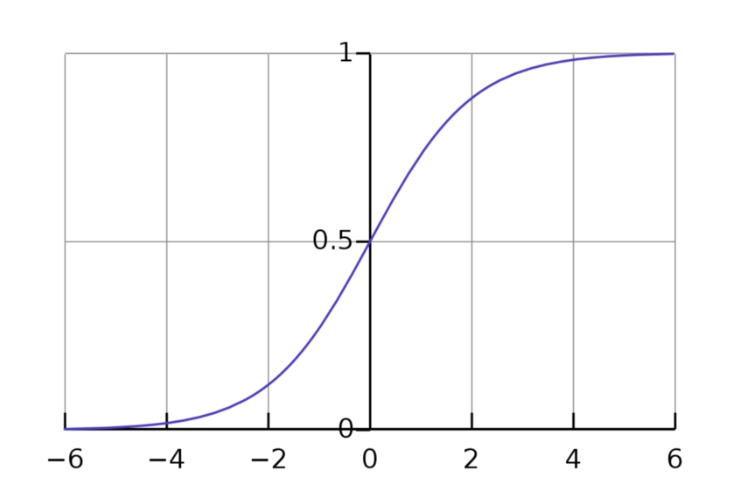
有了这个,我们现在可以插入任何x值并将其追溯到预测的y值。该y值将是该x值在一个类别或另一个类别中的概率。
最大似然估计
你还记得我们是如何通过最小化RSS(有时被称为“普通最小二乘法”或OLS法)的方法在线性回归中找到最佳拟合线的吗?
在这里,我们使用称为最大似然估计(MLE)的东西来获得最准确的预测。
MLE通过确定最能描述我们数据的概率分布参数,为我们提供最准确的预测。
我们为什么要关心如何确定数据的分布?因为它很酷!(并不是)
它只是使我们的数据更容易使用,并使我们的模型可以推广到许多不同的数据。
一般来说,为了获得我们数据的MLE,我们将数据点放在s曲线上并加上它们的对数似然。
基本上,我们希望找到最大化数据对数似然性的s曲线。我们只是继续计算每个log-odds行的对数似然(类似于我们对每个线性回归中最佳拟合线的RSS所做的那样),直到我们得到最大数量。
好了,到此为止我们知道了什么是梯度下降、线性回归和逻辑回顾,下一讲,由Audrey妹子来讲解决策树、随机森林和SVM。
参考链接:
https://towardsdatascience。com/machine-learning-algorithms-in-laymans-terms-part-1-d0368d769a7b
新智元春季招聘开启,一起弄潮AI之巅!
岗位详情请戳:
【春招英雄贴】新智元呼召智士主笔,2019勇闯AI之巅!
【2019新智元AI技术峰会倒计时14天】
2019年的3月27日,新智元再汇AI之力,在北京泰富酒店举办AI开年盛典——2019新智元AI技术峰会。峰会以“智能云?芯世界“为主题,聚焦智能云和AI芯片的发展,重塑未来AI世界格局。
同时,新智元将在峰会现场权威发布若干AI白皮书,聚焦产业链的创新活跃,评述华人AI学者的影响力,助力中国在世界级的AI竞争中实现超越。
购票二维码
活动行购票链接:http://hdxu。cn/9Lb5U
点击文末“阅读原文”,马上参会!
本文首发于微信公众号:新智元。文章内容属作者个人观点,不代表和讯网立场。投资者据此操作,风险请自担。
(责任编辑:HN666)看全文想了解更多关于《》的报道,那就扫码下载和讯财经APP阅读吧





